Django 개발 일기 - 7
Chatterbot을 드디어 올리다, Swap 메모리 사용
by HOON
0
Last updated on Oct. 9, 2024, 2:13 p.m.
챗봇을 드디어 Docker에 올렸습니다.👏🏻
챗봇의 방식은 우하단에 보이게되며 서버의 한계 때문에 많은양의 데이터를 적재하진 못했습니다.
따라서 한글 데이터 부족 + 한정적인 서버 자원으로 인해 챗봇의 성능은 기대할만한 수준이 아니지만,
추후, 서버의 자원을 늘리고, 한글 데이터도 더욱더 훈련 시킬 예정입니다.
서버가 늘어나게되면 ChatGPT로 대체하는 방안도 고려중입니다.
Chatterbot을 Docker에 올리는 과정이 굉장히 험난했는데,
저와 같은 고민을 하는 분들을 위해서 해결과정을 나열해보고자 합니다.
Chatterbot 버전 이슈
현재 python의 pip를 이용하여 chatterbot을 설치할 때, 특정 버전을 지정해주지않으면 기본적으로 chatterbot==1.0.5 버전이 설치가됩니다.
해당 버전이 사용하는 라이브러리 중 spacy==2.1.x 버전이 Docker에서 설치 할 경우 메모리 누수 현상이 있습니다.
(spacy 라이브러리는 Python과 Cython에서 고급 자연어 처리를 위한 라이브러리입니다.)
현재 구현된 서버 환경은 aws lightsail의 제일 낮은 단계이므로 서버 성능을 올릴까 생각도해봤습니다만 구글링결과 메모리가 충분해도, 40분~50분이 소요되면서 설치가 제대로 안된다는 게시글이 있었습니다.
따라서 서버의 성능은 나중에 올리기로하고 다른방법을 찾고있던중 python 3.8.0버전과 chatterbot==1.0.8로 강제 업그레이드를 진행하기로 했습니다.
로컬과 Docker 동일하게 chatterbot==1.0.8을 설치했습니다. (필요한 라이브러리는 chatterbot 설치시 자동 설치가 됩니다.)
이후 build과정 중 문제는 해결되어 정상설치가 되었습니다.
💡Tips.
로컬은 pip install chatterbot==1.0.8로 설치 가능합니다.
Docker는 조금 특이하게 docker-compose build --pararrel 명령어로 도커 내 각 서비스를 독립적으로 Build 진행했습니다.
(이렇게 하면 build하는 속도가 조금이나마 빨라집니다.)
chatterbot 1.0.8이 사용하는 spacy는 현재 제 환경 기준 3.7.4 버전과도 호환이 가능합니다.
Docker 메모리 부족으로, swap 메모리 사용
swap 메모리란
리눅스에서 주 메모리 용량이 부족한경우, 일부 데이터나 프로세스의 디스크 공간을 스왑 메모리로 옮겨 추가적인 공간을 확보하는 방식입니다.
하드나 SSD와같은 보조 저장장치를 사용하여 메모리 부족 상황에서 추가적인 가상 메모리를 제공합니다.
제가 사용중인 lightsail 버전은 메모리가 500mb입니다..ㅎㅎ 따라서 서버가 실행될때마다 챗봇이 데이터를 학습하는데,
이 과정에서 빈번히 out of memory가 발생하여 swap 메모리를 사용하게 되었습니다.swap 메모리 설정방법
우선 free 명령어로 현재 서버의 메모리 상태를 확인해보겠습니다.

저는 이미 swap 메모리를 적용 해 둔 상태여서 swap 메모리 영역이 설정되어 있습니다.
아마 처음 설정하시는 분이라면 swap 메모리 영역이 모두 0으로 설정되어 있을겁니다.
앞서 설명한것과 같이 서버는 500mb를 갖고있고, Mem Total은 467012로 설정되어있습니다. 그 중 used가 315584이고,
free 즉 사용가능 메모리는 10516으로 1mb남짓 남았습니다.
메모리가 부족한 상태에서 swap 메모리를 1gb정도를 추가로 잡아준 상태입니다.
메모리 추가 방법은 아래 명령어를 따라서 입력해주시면 됩니다.
이렇게 리눅스의 swap 메모리를 이용하여 추가적인 가상 메모리를 할당함으로써 조금 더 안정적으로 메모리를 사용 하여 서버를 운영 할 수 있습니다.
sudo dd if=/dev/zero of=/swapfile bs=1024 count=1048576 #swap파일 생성
sudo chmod 600 /swapfile #swap 파일 권한 생성
sudo mkswap /swapfile #swap 스왑 영역 설정
sudo swapon /swapfile #swap 영역 활성화
echo '/swapfile none swap sw 0 0' | sudo tee -a /etc/fstab #fstab 파일에 스왑파일 정보를 추가하여 시스템 부팅 시 스왑 영역이 자동으로 활성화되도록 설정
Docker에서의 라이브러리 코드, Corpus_KOR 폴더의 위치
모든 개발/테스트는 로컬PC에서 이루어집니다. 따라서 로컬PC에서는 당연하게 생각했던부분이, Docker로 옮겨지면서 생각하지못한 변수가 생겼습니다만,
변수가 생기면 경험이라 생각하는 저에겐 환영입니다.
chatterbot을 1.0.5 -> 1.0.8로 마이그레이션 하면서 생긴 변경점 한가지와 로컬->docker서버로 옮기면서 생긴 변경점 한가지를 설명하겠습니다.
1. tagging.py의 수정
마이그레이션을 진행하면서 에러가 발생하는데, 에러는 아래와 같습니다.
OSError: [E941] Can't find model 'en'. It looks like you're trying to load a model from a shortcut, which is deprecated as of spaCy v3.0. To load the model, use its full name instead:
nlp = spacy.load("en_core_web_sm")
번역해보면, spaCy v3.0 버전에서 "en"이라는 모델을 찾을 수 없다고 합니다. 그럼 해당 모델이 어느부분에서 사용되는지 보겠습니다.
아래는 chatterbot 라이브러리 내 tagging.py 스크립트 입니다.
import string
from chatterbot import languages
import spacy
class PosLemmaTagger(object):
def __init__(self, language=None):
self.language = language or languages.ENG
self.punctuation_table = str.maketrans(dict.fromkeys(string.punctuation))
self.nlp = spacy.load(self.language.ISO_639_1.lower()) #여기서 문제 발생!!
def get_bigram_pair_string(self, text):
"""
Return a string of text containing part-of-speech, lemma pairs.
"""
bigram_pairs = []
if len(text) <= 2:
text_without_punctuation = text.translate(self.punctuation_table)
if len(text_without_punctuation) >= 1:
text = text_without_punctuation
document = self.nlp(text)
if len(text) <= 2:
bigram_pairs = [
token.lemma_.lower() for token in document
]
else:
tokens = [
token for token in document if token.is_alpha and not token.is_stop
]
if len(tokens) < 2:
tokens = [
token for token in document if token.is_alpha
]
for index in range(1, len(tokens)):
bigram_pairs.append('{}:{}'.format(
tokens[index - 1].pos_,
tokens[index].lemma_.lower()
))
if not bigram_pairs:
bigram_pairs = [
token.lemma_.lower() for token in document
]
return ' '.join(bigram_pairs)
스크립트를 분석해보면 PosLemmaTagger 클래스는 텍스트를 전처리하고, 품사와 표제어를 추출하여 쌍을 생성하는 클래스인것 같습니다.
즉 chatterbot에서 제일 중요한 부분이라 볼 수 있습니다.
문제는 해당 클래스를 호출하면서 self.nlp = spacy.load(self.language.ISO_639_1.lower()) 이 코드에서 에러가 발생하는데 이유는
spacy 3.x 버전으로 업데이트 되면서 spacy 모듈이 더이상 "en", "ko" 같은 함축적인 표현 대신, "en_core_web_sm"와 같은 디테일한 표현을 채택하여
에러가 발생하고 있었습니다. 따라서 해당 부분을 수정해보겠습니다.
if self.language.ISO_639_1.lower() == 'en':
self.nlp = spacy.load('en_core_web_sm')
else:
self.nlp = spacy.load(self.language.ISO_639_1.lower())
간단하게 분기점을 만들어, "en"모델을 가져오면 'en_core_web_sm' 모델을 load 하도록 설정해줬습니다.
2. data/corpus_KOR 추가
chatterbot을 설치하면 기본적으로 chatterbot-corpus라는 이미 정의된 질의내용의 데이터셋이 같이 설치가 됩니다.
하지만 한글 버전은 따로 설치가 필요하며 github 페이지에서 다운로드 가능합니다. github KOR-corpus
이렇게 데이터를 다운로드하면 Q와 A로 이루어진 yml파일들이 여러개 있는데, 이를 학습시키기 위해서는
lib의 chatterbot-corpus\data 아래 위치에 넣어주면 됩니다.
이제 1번에서 수정한 tagging.py 파일과, 2번에서 새로 다운받아 삽입한 corpus_KOR 파일들을 실제 운영 서버인 도커에서도 수정내역이 반영되도록 수정해야 합니다. (로컬에서는 venv 환경 내 수정을 했다면, 도커는 따로 수정이 적용되지 않기때문에)
도커 내부로 파일을 추가,변경하는 방법은 여러가지가 있지만 저는 Dockerfile 파일에 ADD를 추가하여 넣어보겠습니다.
ADD tagging.py /usr/local/lib/python3.8/site-packages/chatterbot
ADD korean /usr/local/lib/python3.8/site-packages/chatterbot_corpus/data/korean
수정된 파일들은 서버 가동시마다 Docker로 올릴 필요는 없기때문에, Build시 한번만 가동되는 ADD로 넣어주었습니다.
Postgresql 연동
저는 Local에서 테스트시엔 sqlite3, 실제 운영서버는 postgresql로 DB를 나눠서 사용하고 있습니다.
Local에서 처음 chatterbot을 연동하기위해 필요로하는 model을 작성해줬습니다.
이후 Docker에서 chatterbot을 연동할때 문제가 생겼습니다.
sudo docker-compose exec web python manage.py makemigrations chatbot명령어를 작성하여 DB에 chatbot이라는 app 내 models.py를 인식하여 테이블을 새로 만들고자 하였으나 인식하지 못하고 지속적으로 에러가 발생하였습니다.
아래는 makemigrations이 정상적으로 되지 않을 때 고려해볼사항 네가지 입니다.
- settings.py에 INSTALLED_APPS 목록에 존재여부 -> O
- 마이그레이션 폴더에 init.py 파일도 존재여부 -> O
- models.py 파일이 앱의 메인디렉토리에 위치하는지 -> O
- 남은건 데이터베이스와의 연결문제인데 직접 postgresql로 접속해 DB를 살펴보겠습니다.
docker exec -it [실행중인 컨테이너 ID] psql -U [db 접속 유저] -d [db name] 명령어를 입력하면 Docker 서버의 실행중인 postgresql db로 접속이 가능하고 \dt 명령어를 통해 테이블 전체를 볼 수 있습니다.
저는 db에 chatbot의 models.py 내용이 채워지지 않았으므로 강제로 추가하도록 하겠습니다.
CREATE TABLE chatbot_statement (
id SERIAL PRIMARY KEY,
text VARCHAR(255),
in_response_to VARCHAR(255),
search_text VARCHAR(255),
conversation VARCHAR(255),
persona VARCHAR(255),
search_in_response_to VARCHAR(255),
created_at TIMESTAMP
);
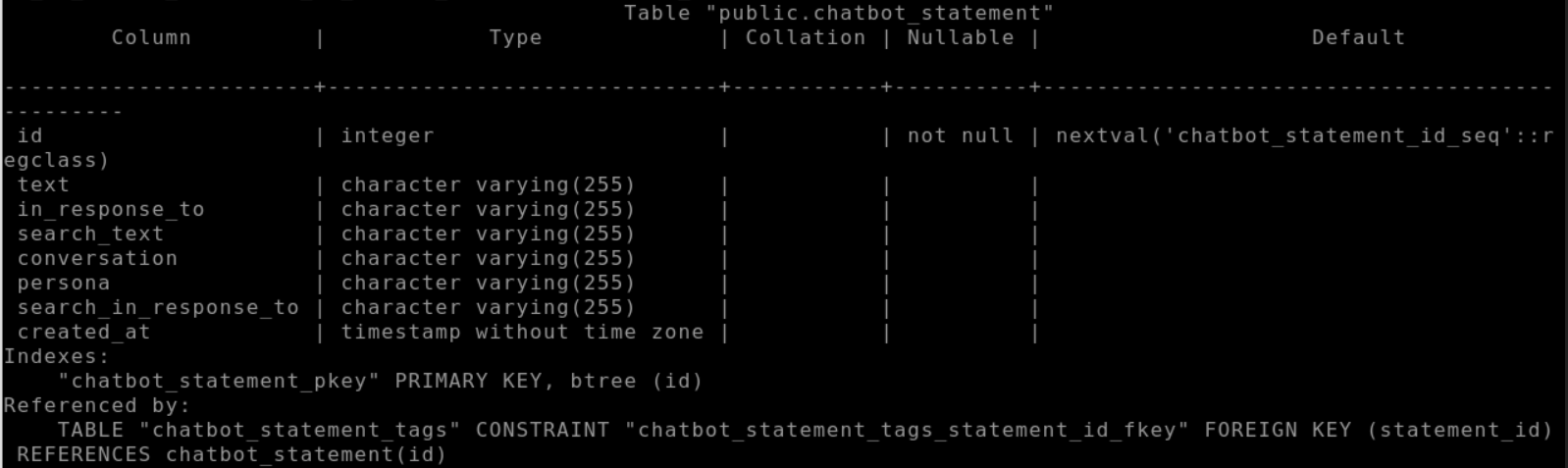
이렇게 postgresql db에 강제로 테이블을 생성하여 데이터를 만들어줬습니다.
나머지 필요한 model도 똑같이 강제로 생성 후 서버를 실행하면
정상적으로 챗봇이 올라간걸 확인할 수 있습니다!
Leave a Comment: