docker야 이사가자 k8s로! - 3
prometheus, grafana
by HOON
1
Last updated on Feb. 12, 2025, 10:29 a.m.
안녕하세요. 오늘은 prometheus, grafana를 docker에서 k8s로 이사시킬건데요,
전과는 다르게 이번엔 Helm을 사용해보겠습니다.
Helm이란 간단하게 Kubernetes(쿠버네티스) 애플리케이션을 쉽게 배포하고 관리할 수 있도록 도와주는 패키지 매니저 입니다.
마치 Mac에서 homebrew를 사용하는 것 처럼요!
Helm을 이용하면 prometheus와 grafana 및 alertmanager 까지 간편하게 설치 할 수 있습니다.
그럼 이제 구현해볼게요.
1. Helm 설치 및 적용
우선 Helm을 사용하기위해 먼저 설치해볼게요.
$ curl https://baltocdn.com/helm/signing.asc | sudo apt-key add -
$ sudo apt-get install apt-transport-https --yes
$ echo "deb https://baltocdn.com/helm/stable/debian/ all main" | sudo tee /etc/apt/sources.list.d/helm-stable-debian.list
$ sudo apt-get update
$ sudo apt-get install helm
그럼 다음 Helm 레포지토리 추가 및 생성된 pod를 확인해볼게요.
#프로메테우스를 위한 Helm 레포지토리를 추가합니다.
$ helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
$ helm repo update
#monitoring이라는 namespace를 생성하면서, 해당 namespace에 prometheus 설치
$ helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring --create-namespace
#현재 활성화된 context가 사용중인 namespace를 확인합니다.
$ k8s-master@k8s-master:~$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
default
* kubernetes-admin@kubernetes kubernetes kubernetes-admin monitoring
monitoring
#생성된 Pod를 확인합니다.
$ k get pods
NAME READY STATUS RESTARTS AGE
alertmanager-my-kube-prom-stack-kube-pr-alertmanager-0 2/2 Running 2 (4m25s ago) 19h
my-kube-prom-stack-grafana-7b6d5c4d5d-p76hd 3/3 Running 3 (4m25s ago) 19h
my-kube-prom-stack-kube-pr-operator-5b7c8b6c44-qk9lc 1/1 Running 1 (4m25s ago) 19h
my-kube-prom-stack-kube-state-metrics-746d4d7db4-sz9vl 1/1 Running 1 (4m25s ago) 19h
my-kube-prom-stack-prometheus-node-exporter-7m482 1/1 Running 1 (4m25s ago) 19h
my-kube-prom-stack-prometheus-node-exporter-gnnjw 1/1 Running 1 (4m29s ago) 19h
prometheus-my-kube-prom-stack-kube-pr-prometheus-0 1/2 CrashLoopBackOff 2 (4m25s ago) 18h
이쯤에서 궁금해지지 않나요?
저는 포트를 지정하고, 테스트기때문에 grafana는 NodePort를 사용하고싶어요.
그 때, manifest파일을 생성하고, helm 설치 시 해당 파일을 지정해주면 됩니다.
#values-monitoring.yaml
prometheus:
enabled: true
prometheusSpec:
replicas: 1
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ""
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
grafana:
persistence:
enabled: true
storageClassName: ""
accessModes: ["ReadWriteOnce"]
size: 1Gi
service:
type: NodePort
nodePort: 30030
파일을 간략하게 설명드리자면, helm으로 설치 될 때, 원하는 옵션을 지정해서 각각 설정 할 수 있어요.
prometheus과 grafana 둘 다 볼륨을 마운트하기 위해 볼륨 관련 내용을 작성했어요.
특이한점은 grafana는 외부에서 접근하기위해 nodePort도 사용했습니다.
이렇게하면 나중에 [http://127.0.0.1:3003](http://127.0.0.1:3003)0 으로 grafana 웹으로 접근 할 수 있겠죠?
2. 에러
근데 이 코드에는 문제가 두 가지 있습니다.
mount가 제대로 되지 않고, 권한 문제가 있어요.
일단 저는 호스트 마운트를 위해 pv를 생성해줬어요. (pvc는 values-monitoring.yaml의 storageSpec.volumeClaimTemplate가 설정되어있기 때문에 바로 생성됩니다.)
# prometheus-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: prometheus-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
# storageClassName가 PVC와 일치하거나, PVC가 storageClassName을 비워놓은 경우 이 PV도 비워야 매칭됨
storageClassName: ""
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /data/k8s/prometheus # 실제 물리 디렉토리
========================================================================
# grafana-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: ""
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /data/k8s/grafana
👉🏻여기서 pvc와 pv가 자동으로 매핑되어 Bound 될 수 있는 조건은,
✅ PVC와 PV의 StorageClass가 일치
✅ PVC의 요청 용량(resources.requests.storage)이 PV의 용량보다 작거나 같아야 함
✅ PVC의 accessModes가 PV의 accessModes를 만족해야 함
그럼 뭔가 이상한게 보이시나요??
용량도 1Gi로 같고, accessModes도 RWO로 같은데 StorageClass까지 “” 으로 동일한게 문제입니다.
이렇게 작성되면 리소스가 생성 될 떄, 서로 다른 pvc와 pv가 연결 될 수 있어요. (제가 그랬습니다..)
따라서 아까 작성한 values-monitoring.yaml 파일을 조금 변경 해 줄게요.
#values-monitoring.yaml
prometheus:
enabled: true
prometheusSpec:
replicas: 1
storageSpec:
volumeClaimTemplate:
spec:
storageClassName: ""
accessModes: ["ReadWriteOnce"]
resources:
requests:
storage: 1Gi
grafana:
persistence:
enabled: true
storageClassName: "grafana-storage"
accessModes: ["ReadWriteOnce"]
size: 1Gi
service:
type: NodePort
nodePort: 30030
========================================================================
# grafana-pv.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: grafana-pv
spec:
capacity:
storage: 1Gi
accessModes:
- ReadWriteOnce
storageClassName: "grafana-storage"
persistentVolumeReclaimPolicy: Retain
hostPath:
path: /data/k8s/grafana
이렇게 하면 pv,pvc를 매핑 할 떄, 서로 같은 storageClassName을 우선적으로 매핑하기때문에
정확하게 매핑되어 바운드 시킬 수 있습니다.
그럼 이대로 다시 설치하고 적용해볼게요.
$ helm install prometheus prometheus-community/kube-prometheus-stack --namespace monitoring -f values-monitoring.yaml
#
prometheus-my-kube-prom-stack-kube-pr-prometheus-0 1/2 CrashLoopBackOff 2 (4m25s ago) 18h
이상해요, 에러가 발생했는데 이유가 뭘까요?? 우선 describe로 pod의 이벤트를 확인해볼게요.
node.kubernetes.io/unreachable:NoExecute op=Exists for 300s
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedScheduling 27s default-scheduler 0/2 nodes are available: pod has unbound immediate PersistentVolumeClaims. preemption: 0/2 nodes are available: 2 Preemption is not helpful for scheduling.
Normal Scheduled 26s default-scheduler Successfully assigned monitoring/prometheus-my-kube-prom-stack-kube-pr-prometheus-0 to k8s-node1
Normal Pulled 23s kubelet Container image "quay.io/prometheus-operator/prometheus-config-reloader:v0.80.0" already present on machine
Normal Created 23s kubelet Created container init-config-reloader
Normal Started 22s kubelet Started container init-config-reloader
Normal Pulled 20s kubelet Container image "quay.io/prometheus-operator/prometheus-config-reloader:v0.80.0" already present on machine
Normal Created 20s kubelet Created container config-reloader
Normal Pulled 19s (x2 over 21s) kubelet Container image "quay.io/prometheus/prometheus:v3.1.0" already present on machine
Normal Created 19s (x2 over 21s) kubelet Created container prometheus
Normal Started 19s kubelet Started container config-reloader
Normal Started 18s (x2 over 20s) kubelet Started container prometheus
Warning BackOff 10s (x6 over 17s) kubelet Back-off restarting failed container prometheus in pod prometheus-my-kube-prom-stack-kube-pr-prometheus-0_monitoring(5470c8aa-9adf-4495-b825-279fe7990542)
k8s-master@k8s-master:~/monitoring-yaml$ k logs prometheus-my-kube-prom-stack-kube-pr-prometheus-0
time=2025-02-11T02:27:33.345Z level=INFO source=main.go:683 msg="Starting Prometheus Server" mode=server version="(version=3.1.0, branch=HEAD, revision=7086161a93b262aa0949dbf2aba15a5a7b13e0a3)"
time=2025-02-11T02:27:33.345Z level=INFO source=main.go:688 msg="operational information" build_context="(go=go1.23.4, platform=linux/amd64, user=root@74c225e2044f, date=20250102-13:52:43, tags=netgo,builtinassets,stringlabels)" host_details="(Linux 5.4.0-144-generic #161-Ubuntu SMP Fri Feb 3 14:49:04 UTC 2023 x86_64 prometheus-my-kube-prom-stack-kube-pr-prometheus-0 (none))" fd_limits="(soft=1048576, hard=1048576)" vm_limits="(soft=unlimited, hard=unlimited)"
time=2025-02-11T02:27:33.349Z level=INFO source=main.go:764 msg="Leaving GOMAXPROCS=2: CPU quota undefined" component=automaxprocs
time=2025-02-11T02:27:33.350Z level=ERROR source=query_logger.go:113 msg="Error opening query log file" component=activeQueryTracker file=/prometheus/queries.active err="open /prometheus/queries.active: permission denied"
panic: Unable to create mmap-ed active query log
goroutine 1 [running]:
github.com/prometheus/prometheus/promql.NewActiveQueryTracker({0x7ffde0ff4f21, 0xb}, 0x14, 0xc000998780)
/app/promql/query_logger.go:145 +0x345
main.main()
/app/cmd/prometheus/main.go:791 +0x822c
이벤트에 적힌 내용을 보니, /prometheus/queries.active 이 파일에 접근 할 수 있는 권한이 없다네요.
구글링을 좀 해보니, kube-prometheus-stack에서 배포되는 Prometheus 컨테이너는 루트 권한이 아닌 다른 UID/GID(예: 65534:65534 (nobody) 등)로 실행된다고 해요.
즉, 저희가 hostPath: /data/k8s/prometheus를 PV로 마운트한 경우, 기본적으로 호스트 디렉터리는 root:root 소유이고, 퍼미션이 제한되어 있을 가능성이 높다고 해요.
결과적으로 컨테이너 내부에서 /prometheus 경로(=호스트 /data/k8s/prometheus)에 대해 쓰기 권한이 없는 것 같아요.
그럼 실제로 리소스 생성시 runAsUser과 runAsGroup에 어떤 값이 들어가있는지 확인하고 맞게 수정할게요.
$ kubectl get pod prometheus-my-kube-prom-stack-kube-pr-prometheus-0 \
> -n monitoring \
> -o jsonpath='{.spec.securityContext}'
{"fsGroup":2000,"runAsGroup":2000,"runAsNonRoot":true,"runAsUser":1000,"seccompProfile":{"type":"RuntimeDefault"}}
#runAsUser: 1000, runAsGroup: 2000으로 설정이 되어있네요!
#그럼 아래와 같이 user/group을 지정하고 혹시 모르니 폴더의 권한도 설정하겠습니다.
k8s-master@k8s-master:~/monitoring-yaml$ sudo chown -R 1000:2000 /data/k8s/prometheus
k8s-master@k8s-master:~/monitoring-yaml$ sudo chmod -R 770 /data/k8s/prometheus
k8s-master@k8s-master:~/monitoring-yaml$ ls -ld /data/k8s/prometheus
drwxrwx--- 2 k8s-master 2000 4096 Feb 11 01:23 /data/k8s/prometheus
만약!!! 이렇게 해도 안되는데, 해결은 해야겠다!! 하시는분은 퍼미션 자체를 root로 올려서 시도해보세요.
Permission issues
보안상 권장되는 해결방법은 아니겠지만, 단순하게 해결 할 수 있습니다.
securityContext:
fsGroup: 2000
runAsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
seccompProfile:
type: RuntimeDefault
👇🏻👇🏻👇🏻
securityContext:
fsGroup: 0
runAsGroup: 0
runAsNonRoot: false
runAsUser: 0
$ helm upgrade my-kube-prom-stack prometheus-community/kube-prometheus-stack -n monitoring -f values-monitoring.yaml
3. 되나?
권한도 올려줬으니, 이제 접속 테스트를 해볼게요. 그 전에 pod가 정상작동중인지 먼저 확인해볼까요?
$ k get pods
NAME READY STATUS RESTARTS AGE
alertmanager-my-kube-prom-stack-kube-pr-alertmanager-0 2/2 Running 2 (64m ago) 20h
my-kube-prom-stack-grafana-7b6d5c4d5d-p76hd 3/3 Running 3 (64m ago) 20h
my-kube-prom-stack-kube-pr-operator-5b7c8b6c44-qk9lc 1/1 Running 1 (64m ago) 20h
my-kube-prom-stack-kube-state-metrics-746d4d7db4-sz9vl 1/1 Running 1 (64m ago) 20h
my-kube-prom-stack-prometheus-node-exporter-7m482 1/1 Running 1 (64m ago) 20h
my-kube-prom-stack-prometheus-node-exporter-gnnjw 1/1 Running 1 (64m ago) 20h
prometheus-my-kube-prom-stack-kube-pr-prometheus-0 2/2 Running 2 (64m ago) 19h
모두 Running으로 정상작동 중이네요!
그럼 로컬 웹에서 접속해볼까요??
근데 생각해보니 NAT 네트워크를 사용중이니까 포트포워딩 해줄게요.
30030 → 30030으로 설정하면 됩니다.
그 다음 접속 확인해보면???
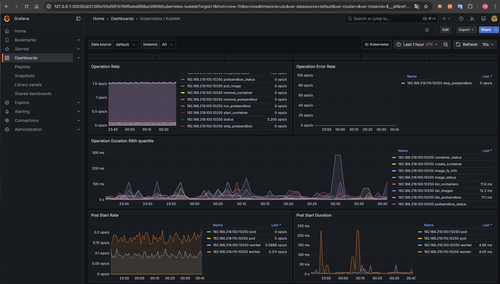
정상 작동 되는걸 확인 할 수 있습니다!!
이상으로 docker -> k8s 시리즈는 마무리 하도록 하겠습니다!
감사합니다.
Leave a Comment: