k8s cluster 대용량 트래픽 테스트
k6를 사용한 부하 테스트
by HOON
1
Last updated on March 21, 2025, 2:18 p.m.
안녕하세요, 오늘은 pda 최종 프로젝트를 진행하면서 해보고싶었던 대용량 트래픽 테스트를 진행해보겠습니다.
우선 저는 EC2 여러개로 직접 K8s 클러스터를 구축했습니다.
그리고 분산처리를 쉽게 하기 위해서 인스턴스 유형을 t3.large(2cpu, 8gb ram)을 사용했습니다.
또한 대용량 트래픽 테스트에는 k6라는 cli 기반 툴을 사용하였습니다.
기본적으로 k8s는 HPA를 사용하면, 자동으로 현재 지정한 cpu나 다른 custom metric(memory 혹은 db-connection 등)의 기준치를 초과하면 자동으로 pod를 지정한 숫자만큼 늘릴 수 있습니다.
우선 저희는 be-stock 서비스에 대용량 트래픽을 전송해볼게요.
k6 사용
k6는 비교적 최근에 나온 대용량 트래픽 툴 이라고 알고있습니다. cli 기반 js코드로 작성 가능하며, cicd와의 통합도 지원합니다.
그럼 이제 테스트를 위한 스크립트를 작성해볼까요??
$ cat load_test.js ✔ took 3m 4s
import http from "k6/http";
import { sleep, check } from "k6";
export let options = {
vus: 2000, // 동시 가상 사용자 수 (필요에 따라 조정)
duration: "3m", // 테스트 실행 시간 (3분)
thresholds: {
http_req_duration: ["p(95)<500"], // 95% 요청의 응답시간이 500ms 이하
},
};
export default function () {
// stock 서비스 엔드포인트에 GET 요청
let res = http.get("https://api.inst00ck.shop/stocks/rankings/top20");
check(res, { "status is 200": (r) => r.status === 200 });
sleep(0.1); // 0.1초 대기 후 다음 요청 실행
}
저는 저희 서비스의 stocks 서비스의 랭킹을 가져오는 부분에 get 요청을 보내볼게요
2000명이 동시접속해서 테스트를 3분동안 0.1초 간격으로 진행하도록 작성해줬습니다.
HPA 사용
분명 t3.large이라 조금만 트래픽이 몰려도 부하가 걸릴거에요. 그럼 자동으로 Pod가 늘어나면서 분산처리가 되면 좋을것같습니다.
hpa를 생성해볼게요.
ubuntu@k8s-master:~/backend/prod-stock$ cat be-stock-hpa.yaml
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
metadata:
name: be-stock-hpa
namespace: be-namespace
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: be-stock
minReplicas: 1
maxReplicas: 5 # 부하에 따라 최대 5개까지 스케일 아웃
metrics:
- type: Resource
resource:
name: cpu
target:
type: Utilization
averageUtilization: 70 # CPU 사용률이 60% 이상일 경우 스케일 아웃
cpu 사용률이 70%를 오버하게되면 최소 파드 개수 1→5 까지 늘어나도록 작성해줬습니다.
(실제 테스트는 부하를 쉽게 걸기위해 30%로 설정했습니다.)
그럼 이제 저희가 아까 작성한 테스트 js 코드를 사용해서 k6를 통해 부하를 걸어볼게요.
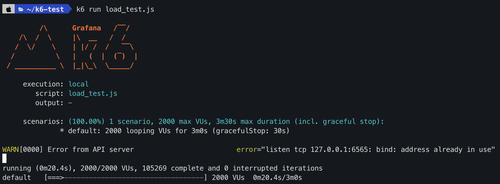
동시에 htop으로 실제 서비스가 가동중인 노드의 상태를 살펴볼게요.
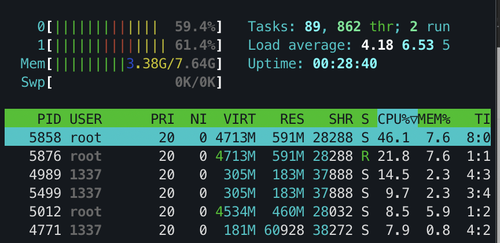
cpu가 벌써 30%를 넘어서 60%~70%까지 상회하고있어요.
그럼 이제 진짜 대용량 트래픽이 들어올경우 pod가 자동으로 스케일아웃 되는지 확인해볼까요??

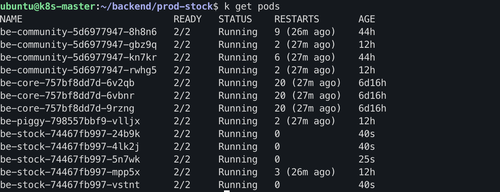
정상적으로 파드가 5개까지 생성되었습니다! 이렇게 지정한 메트릭을 추적하면서 기준치를 초과했을때 k8s는 pod를 늘려서 분산처리를 자동으로 해줄 수 있습니다.
근데 뭔가 부족한거같아요. pod는 몇개씩 늘릴 수 있지만, 실제로 pod가 존재하는 node가 견딜 수 없는 트래픽이라면?? 그럼 분명 서비스가 다운될거에요.
AWS AutoScailing
아까 제가 말씀드린 환경은 AWS EC2를 사용해서 직접 클러스터를 구축했다고 했습니다.
그렇다면 EC2 노드에 부하가 걸릴경우 AutoScailing을 사용 할 수 있겠죠?
AutoScailing도 트래픽이 몰릴 경우 지정해둔 템플릿에 따라 노드를 추가로 생성 해주는 기능이에요.
저희는 트래픽이 몰릴 때 hpa로 1차 대응을 하고, 더욱 많은 트래픽은 AutoScailing을 사용해서 노드를 한개 더 생성해주도록 할게요.
AutoScailing을 생성하는 방법은 구글링하면 참고자료가 많이때문에 여기서는 다루지 않겠습니다.
다만, 저희는 k8s를 사용하고있고, 직접 클러스터를 구축했기때문에 노드가 생성되면 실제 저희 k8s 클러스터에 join을 해줘야해요. 그래야 인식이되고 서비스를 안정적으로 늘릴 수 있으니깐요.
우선 제가 이번 클러스터를 구축하면서 아래와 같은 순서로 명령어를 작성하고 클러스터를 join했습니다. 이 내용을 그대로 시작템플릿에 작성해줄게요.
#!/bin/bash
set -e
# 1. Swap 비활성화
sudo swapoff -a
sudo sed -i '/swap/d' /etc/fstab
# 2. 필수 커널 모듈 및 sysctl 설정
cat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
br_netfilter
EOF
sudo modprobe br_netfilter
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.ipv4.ip_forward=1
EOF
sudo sysctl --system
# 3. containerd 설치 및 설정
sudo apt-get update
sudo apt-get install -y containerd
# 기본 설정 파일 생성
sudo mkdir -p /etc/containerd
sudo containerd config default | sudo tee /etc/containerd/config.toml >/dev/null
# SystemdCgroup 값을 true로 설정 (기존 값이 false일 경우 변경)
sudo sed -i 's/SystemdCgroup = false/SystemdCgroup = true/g' /etc/containerd/config.toml
# containerd 서비스 활성화 및 시작
sudo systemctl enable containerd --now
sudo systemctl restart containerd
# 4. Kubernetes 패키지 설치 (kubelet, kubeadm, kubectl)
sudo apt-get upgrade -y
sudo apt-get install -y apt-transport-https ca-certificates curl gpg
sudo mkdir -p -m 755 /etc/apt/keyrings
curl -fsSL https://pkgs.k8s.io/core:/stable:/v1.29/deb/Release.key | sudo gpg --dearmor -o /etc/apt/keyrings/kubernetes-apt-keyring.gpg
echo 'deb [signed-by=/etc/apt/keyrings/kubernetes-apt-keyring.gpg] https://pkgs.k8s.io/core:/stable:/v1.29/deb/ /' | sudo tee /etc/apt/sources.list.d/kubernetes.list
sudo apt-get update
sudo apt-get install -y kubelet kubeadm kubectl
# 5. 클러스터에 join (아래 값들은 여러분의 클러스터 환경에 맞게 수정)
sudo kubeadm join <Master IP>:6443 --token <KEY> --discovery-token-ca-cert-hash <HASH>
그럼 실제로 대용량 트래픽 테스트 중 인스턴스가 하나 더 생기는지 볼까요?
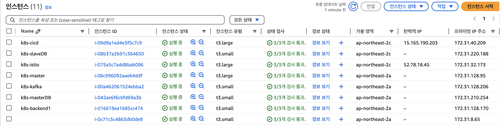
태그를 지정하지 않아서 이름은 없지만, 인스턴스가 한개 더 생겼어요.
그럼 해당 인스턴스가 진짜 저희가 작성한 템플릿 내용에 따라 k8s를 설치하고 join까지 했을까요??

“join”으로 grep 했더니 잡히는게 있네요!
master node에서도 확인해보면..
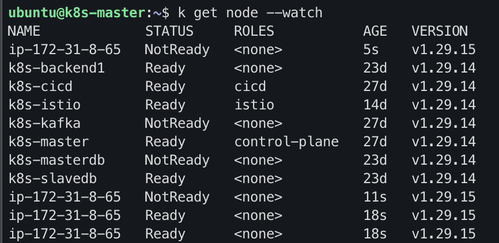
자동으로 생성된 노드 (172.31.8.65)에 대해서 자동으로 저희 k8s 노드에 Join되어 Ready 상태로 변경되었습니다~!
이제 부하가 걸리더라도 저희가 지정해둔 AutoScailing을 통해 자동으로 node가 생성 및 Join 되어
조금이나마 분산처리에 도움이 될 것 같아요.
Leave a Comment: