Instock - 신뢰할 수 있는 투자 정보 SNS
by HOON
0
Last updated on March 21, 2025, 1:56 p.m.
프로젝트 개요
Instock은 기존 주식 커뮤니티가 가진 문제점을 해결하고, 초보 투자자부터 숙련된 투자자까지 모두가 신뢰할 수 있는 주식 SNS 플랫폼을 제공하기 위해 탄생한 서비스입니다.
해당 프로젝트에서 저는 댓글 기능의 CRUD를 맡고, 배포 전부를 맡았습니다.
저희 프로젝트는 MSA 기반이기 때문에 서비스 관리가 용이한 Kubernetes를 사용하기로 했습니다. (사실 자격증을 따고 얼마 지나지 않아서 써보고싶어습니다.)
Infra
우선, 제가 작성/구축한 인프라 구성도를 보겠습니다.
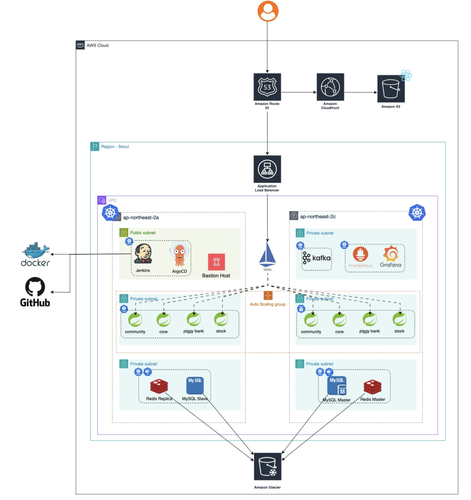
각각의 리소스에 대해서 설명을 드리겠습니다.
1. 아키텍처 개요
- AWS EC2 인스턴스를 이용한 Kubernetes 클러스터 구성
- 서비스는 각각의 리소스 및 역할에 따라 분리 구성
- Public 및 Private 서브넷을 명확히 구분하여 보안성 강화
2. 인프라 구성 상세
- Public Subnet
- Jenkins를 이용한 CI 환경 구축
- ArgoCD를 이용한 CD 파이프라인 자동화
- Private Subnet
- Kubernetes 클러스터 및 서비스 전반 운영
- 데이터베이스(MySQL, Redis)의 Master/Slave 복제 구성
- DNS 서비스는 Route53을 사용하여 inst00ck.shop 도메인 관리
- CDN 서비스로 CloudFront를 도입해 트래픽 효율화 및 성능 최적화
- 정적 리소스(이미지, JS, CSS 등)는 AWS S3 버킷을 통해 서비스
- 동적 트래픽은 AWS Load Balancer가 수신 후 Kubernetes 클러스터 내부에서 Istio 서비스 메쉬를 통해 정교하게 라우팅
3. CI/CD 파이프라인
- CI: Jenkins를 통해 자동 빌드, 테스트 및 도커 이미지 생성 자동화
- CD: ArgoCD를 활용하여 GitOps 기반의 배포 자동화 및 버전 관리
4. 데이터베이스 구성 및 관리
- MySQL 및 Redis를 각각 Master/Slave 복제 구조로 운영하여 데이터 무결성과 고가용성 확보
- 성능 및 데이터 일관성 유지
5. Monitoring
- Prometheus를 사용해 서비스 메트릭 추적
- Grafana 사용하여 CPU, Mem 사용량 혹은 Custom Metric등 다양한 정보를 시각화
6. 백업 및 복구 전략
- 주기적으로 데이터베이스 데이터를 AWS S3 Glacier로 백업
- 장기 보관 및 저비용으로 데이터 손실 위험 최소화
후기
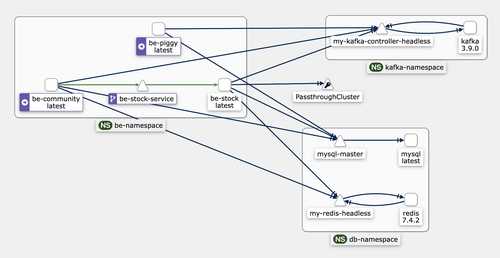
이번 프로젝트에서 저는 팀원들의 요구에 따라 Kafka를 위한 설계를 따로 해줬어야 하는데요.
처음 접하는 기술이다보니 설계 자체에서도 어려움이 있었습니다.
Operator인 bitnami/kafka를 사용했고, Kraft 모드를 사용해서 따로 Broker 파드 없이, Controller 파드로 관리 할 수 있었습니다.
해당 트러블슈팅에 대해서는 다음 경로에 포스트했으니 참고 부탁드립니다.
Kafka 트러블슈팅 in k8s
또한 istio를 한번 사용해봤는데요.
원래는 k8s의 ingress 리소스를 사용하려고 했습니다.
하지만 istio의 트래픽 추적과 보안성에 크게 매료되어 istio를 선택하게 되었어요.
덕분에 kiali 같은 툴을 사용해서 실제 서비스의 트래픽을 추적 할 수 있었습니다.
마지막으로, 이번 프로젝트에서 예산이 30만원으로 한정되어있었습니다.
따라서 EKS를 사용하지않고 직접 ec2에 클러스터를 구축했으며 ec2 인스턴스도 t3.small로 시작하여 서버에 부하가 걸리는 경우 인스턴스 유형을 점진적으로 scale up 하는 방식으로 진행했으며, mysql이나 redis도 직접 RDS 혹은 ElasticCache같은 서비스를 사용하지않고
직접 구축하면서 비용을 절감하는 방식으로 진행했습니다.
Leave a Comment: